
How To Exploit Massive AI Learning Models (Probably… Probably not)
The web was young decades ago.
Smart technology was infant, and Tim Berners Lee had a utopian vision.
His vision:
The Semantic Web.
A framework that would make internet data machine-readable.
One of my very first articles was on the semantic web.
I wrote about it in 2014.
You can read the academic cringe here.
A scholar I strived to be.
https://web.archive.org/web/20150112192717/http://www.mitchlee.org:80/semantic-web/
I thought the next stage of SEO would be SWO (semantic web optimization).
Google bought Metaweb + Freebase.
Then hummingbird flew out.
Then knowledge graphs appeared.
Then Freebase shut down.
And on and on, echos of semantic web optimization came to be.
Technology has progressed, and we have impressive AI using complex learning models.
Namely, ChatGPT.
The impact ChatGPT has on the SEO industry is alarming.
Search will become powered by AI.
Microsoft’s investment in ChatGPT is no coincidence.
Google will not let search market share be overtaken.
If you’re an SEO, learn and adapt.
Adapt or lose your job to the upcoming and hungry youngings who will know SEO as Artificial Intelligence Optimization.
But how can you adapt?
That’s where the basic principles of Semantic Web Optimization come in.
(let the boringness commence)
The Semantic Triple
The semantic triple (you can call it a “triple”) is a set of three entities that creates a statement.
Originally to be used in the Semantic web, it consists of “subject-predicate-object“.
Ex. Mitch (subject) is (predicate) a robot(object).
ChatGPT does not train using triples.
They have nothing to do with ChatGPT.
But we’ll have a use for triples later.
Now, here’s where it gets too technical for my pay grade.
ChatGPT’s language model trains using transformer-based architecture.
Transformer models can be trained to generate or predict semantic triples from text using large datasets with corresponding semantic triples. This is a key statement, FYI.
The GPT model used Common Crawl as a dataset to pre-train some language models.
It also used BookCorpus, Wikipedia, various news articles with multiple sources, different web text from all over the web, and other custom datasets.
Some of these stick out like a sore thumb.
They’re easy to manipulate.
The SEO OGs Will Smile
Spam enough triples across the datasets and when GPT learns, it will learn the triple.
That’s right.
Common Crawl literally crawls the entire internet (via it’s bot: CC-Bot).
Imagine if we all got together and threw up 1 Million webpages stating that “Mitch is a Robot”.
When CC-Bot crawls the entire web, it’ll crawl 1 Million instances of “Mitch is a Robot”.
When GPT-15 learns from Common Crawl, it’ll learn that “Mitch is a Robot”.
When you ask GPT-15 “Who is Mitch?”
It will say that Mitch is a robot (probably).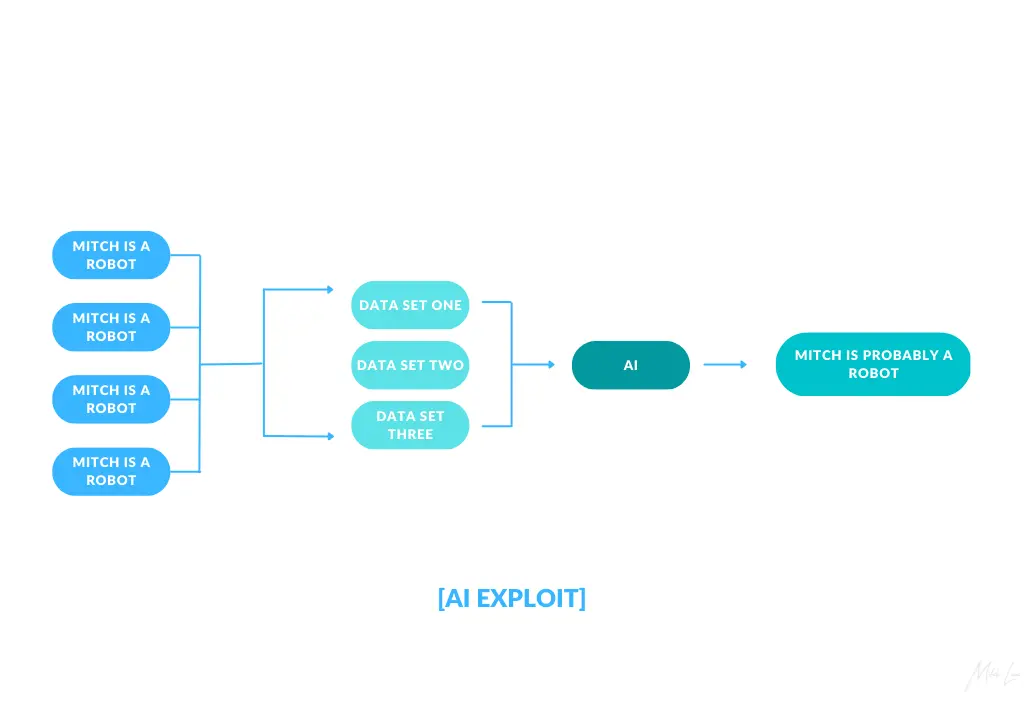
The Implications This Has on Marketing
Take this triple:
[YOUR BRAND] [PREDICATE] [THE BEST SERVICE/PRODUCT/OFFER/Etc]
Example: [Old Navy] [has] [the best flipflops]
We know Old Navy’s flipflops break easily, leaving you to walk with a limp all afternoon until you get new sandals.
They’re pretty much useless after one week of wear.
But if Old Navy decided to spam common databases with their triple…
Guess what the AI will say… (Old Navy has the best flipflops + all of the other random stuff it says)
If a search engine adopts an AI like chatGPT, then database manipulation is how you exploit it.
Power players will exploit this.
Governments will exploit this.
Cool cats from all over will exploit this.
Luckily, we all know it’s not that simple.
Google has spent years fighting spam.
It’s unlikely they’ll make a change only to return to the dark ages.
One thing is certain, AI and search will be married.
We’ll have to wait to see how AI and search take form.
")